Uno de los mantras más escuchados entre los profesionales del marketing digital y que te habrás hartado de oír es que el SEO toma su tiempo. Podemos afirmar que es la versión moderna del lema “Roma no se construyó en un dia”.
Por eso, uno de los mayores retos que tenemos en nuestra Agencia de Posicionamiento SEO cuando arrancamos un nuevo proyecto, está en dar con la tecla que nos permita lanzar el dominio de un cliente en las SERPs en poco tiempo. Precisamente, este es el caso que veremos hoy.
En el Caso de Éxito SEO Indexación veremos comó hemos ayudado a despegar en solo 6 semanas (21 días si quitamos el tiempo de la auditoría) a web de clasificados en alemán con aspiración multipaís a la que hemos ayudado a tras más de 12 meses estancada.
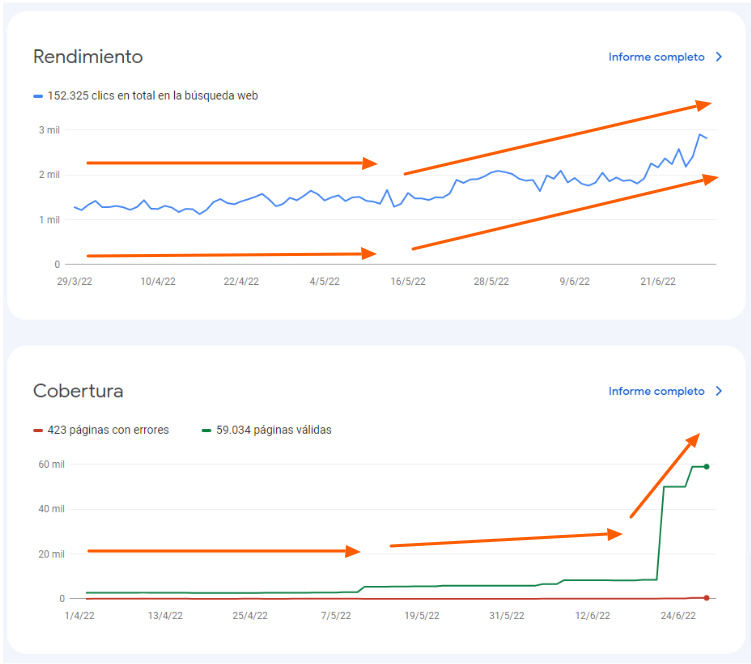
En tan solo 21 días, hemos conseguido los siguientes resultados:
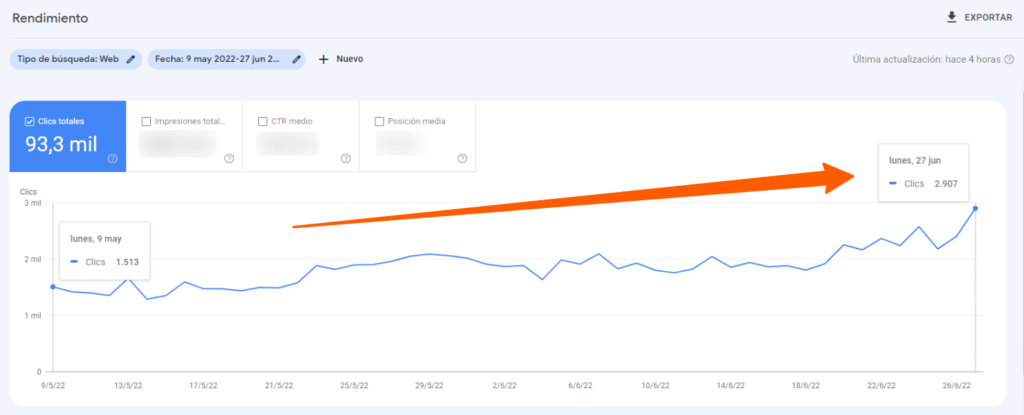
- ∆ 92% de visitas orgánicas pasando de 1.513 a 2.907 clics diarios.
- ∆ 85,76% de impresiones en Google pasando de 14.780 resultados mostrados a 27.308 apariciones en las SERPs.
Y todo esto, gracias a que en poco más de 21 días tras la auditoría SEO hemos disparado la indexación del proyecto de 8k URLs a casi 60k. Lo que explica el subidón en impresiones y clics.
Punto de Partida: Un Proyecto estancado desde Junio de 2021
Para comprender mejor lo conseguido es necesario describir el contexto del estado del proyecto antes de nuestra intervención. Partimos de un dominio que venía de sufrir una importante caída de tráfico orgánico que la propiedad consiguió estabilizar. Sin embargo, en los últimos 12 meses se veía una falta total de progreso.
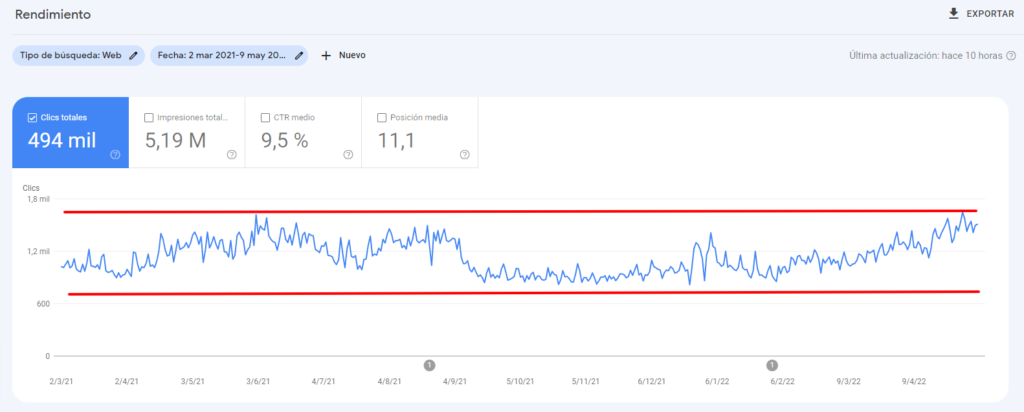
El tráfico orgánico diario en este periodo estaba estancado en una banda que oscilaba de 820 a 1.623 visitas diarias. Algo insuficiente para nuestro cliente. Además, en estos casos, existe un riesgo alto de sufrir una recaída. Ya sabéis que en SEO rara vez existen las tendencias planas. O se sube o se baja.
Y es que, por lo general, la situación se estabiliza tras realizar algunos arreglos pero el problema de fondo rara vez queda 100% resuelto por lo que Google tarde o temprano, vuelve a dejar de mostrar la página en las primeras posiciones de sus resultados.
El Reto: Cómo abrir el rastreo para miles de URLs sin destapar la caja de pandora SEO
Por fortuna, la auditoría SEO del dominio reveló que existían problemas de rastreo e indexación:
- Por un lado, a través del robots.txt, se estaba impidiendo que los buscadores rastrearan las versiones en otros idiomas de la página web.
- Al mismo tiempo, las fichas creadas por los usuarios en la web no conseguían indexar correctamente.
- Una mala configuración de las páginas de categorías enlazando a versiones parametrizadas de las fichas que a su vez apuntaban a la versión original mediante un rel=”canonical”, estaba evitando la indexación de esos contenidos por parte de los buscadores. Dejando una gran cantidad de URLs con valor SEO sin posibilidad de posicionar.
- Además, la configuración de las paginaciones de la web era deficiente. Solo se indexaba la página principal de la categoría y el resto de páginas se mantenían con una directiva noindex.
Estos tres puntos:
- Paginación de categorías sin optimizar.
- Fichas sin indexar.
- Versión de la web en otros idiomas bloqueadas.
Estaban provocando que miles de URLs quedarán sin rastrear ni indexar. Evitando que el proyecto pudiera despegar.
La duda: ¿Tendremos suficiente presupuesto de rastreo para destapar todo el dominio?
Resultaba evidente que el proyecto necesitaba conseguir la indexación de todas las URLs con valor de posicionamiento. Pero, si llevas tiempo en el mundo del SEO, sabes que una operación de destape para un volumen elevado de URLs no está exenta de riesgos.
Para que nos entendamos:
Abrir el rastreo en un proyecto de estas dimensiones es como abrir una botella de champán recién sacada del tambor de una lavadora centrifugando a 1.800 RPM.
Cuando lo haces, vas a subir como la espuma pero justo después vendrá la caída perdiendo la mayoría del tráfico conseguido.
Y es que, al facilitar la indexación de miles de URLs te vas a encontrar seguro con problemas que van desde la falta de presupuesto de rastreo a canibalizaciones, pasando por contenidos duplicados, urls sin contenido etc…
Por eso mismo, toda esta fuerza acumulada debe controlarse. Entonces ¿Cómo manejar una situación tan explosiva como esta?
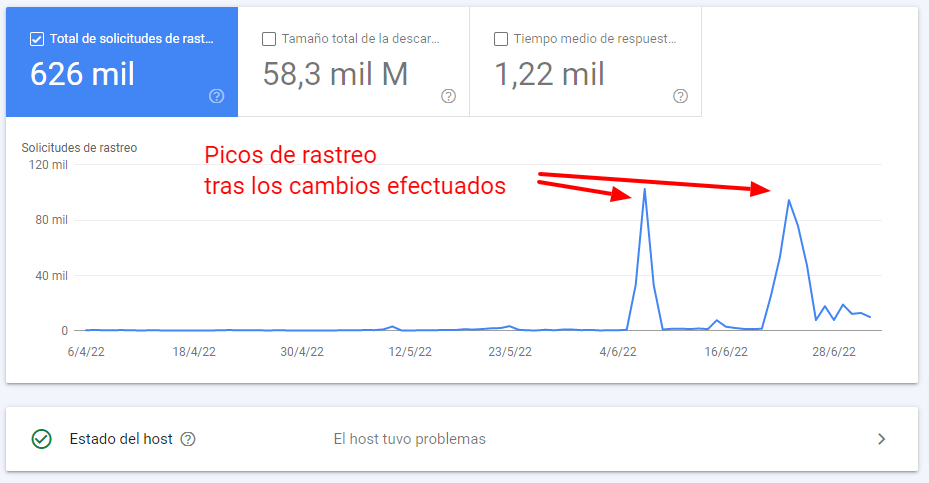
Primero, comprobamos en GSC las estadísticas de rastreo para identificar problemas y sanear el proyecto hasta dejarlo en unos parámetros razonables como los de la gráfica:
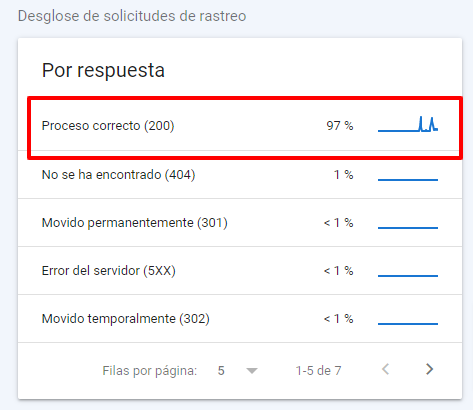
Como ves en la imagen anterior, ahora mismo contamos con un 97% de urls mostrando códigos 200 por lo que el % de URL con problemas es mínimo.
Segundo, nos aseguramos de que no tendríamos problemas de presupuesto de rastreo.
En este caso, el dominio ya contaba con cierta autoridad y al mismo tiempo, encontramos indicios de que Google ya estaba rastreando, indexando y posicionando incluso páginas en otros idiomas bloqueadas por robots.txt. De hecho, algunas de estas URLs aportan ya bastante tráfico orgánico al dominio.
Esto despejaba nuestra dudas iniciales para abrir el rastreo sin temor a quedarnos sin recursos. Lo que nos animó a seguir con la estrategia.
La solución: abrir la indexación a las fichas, paginaciones estilo iSocialweb + arreglos técnicos para facilitar el rastreo
Dado que a corto plazo no puedes aumentar la autoridad de un dominio ni tampoco el presupuesto de rastreo, hay que balancear muy bien la apertura para no agotar los recursos que Google tiene asignado a tu proyecto. Nada más terminar la auditoría y hablar con la propiedad se decidió:
Paso 1: Arreglar el enlazado a las fichas desde las categorías
El 9 de junio se iniciaron los trabajos para la corrección de las categorías que enlazaban a URLs de fichas a través de variables para parametrizar los clics. Se le transmitió a la propiedad que esto era posible hacerlo con datalayer sin tener que crear nuevas URLs. Además, todas estás páginas contenían un canonical apuntando a su versión original.
Por lo tanto, se sustituyeron las URLs parametrizadas al mismo tiempo que las redireccionamos con un 301 a su homólogo original. Así dejamos claro a Google cuál era la versión de las fichas que debía indexar.
Recuerda que hasta esa fecha desde las categorías se estaba enlazando a fichas de anuncios clasificados mediante una URL con parámetros que contenía un rel=”canonical” apuntando a la URL original.
El problema es que está es una señal muy débil.
Debemos tener en cuenta que el canonical es una sugerencia (no una directiva) y Google no tenía claro qué versión de URL tener en cuenta y acabó por no indexar ninguna de estas URLs con gran potencial de posicionamiento por estar duplicadas. Un error que quedaba por fin subsanado.
Paso 2: Abrir el rastreo a las versiones de la web en otros idiomas
Casi al mismo tiempo procedimos a actuar sobre las diferentes versiones en otros idiomas de la web. La web cuenta con 7 idiomas diferentes. Cuando arrancamos, 6 de ellos estaban bloqueados en el robots.txt e incluso con directiva noindex.
Aquí, se actuó en dos partes:
- Para los idiomas sin interés de negocio (ES, RU y HU) procedimos a ofuscar todos los enlaces de estas versiones y poner una etiqueta noindex para prevenir su indexación.
- Para el resto de idiomas con valor de negocio (DE, FR y EN) retiramos la etiqueta noindex que no tenía ningún sentido y se configuraron correctamente las etiquetas hreflang indicando el lenguaje y el país donde se enfoca el negocio (en este caso suiza CH)
Por último, en ambos casos eliminamos el bloqueo de estos directorios en el robots.txt. Así el rastreo solo quedaba abierto para las versiones en los idiomas que nos interesaban. Todo ello quedó solucionado para el 13 de junio y empezamos a notar los primeros resultados positivos.
Paso 3: Eliminar versión duplicada del blog
Mientras le dábamos tiempo a Google para ir rastreando las URLs de las fichas y paginaciones, solucionamos un problema de contenidos duplicados relacionados con el blog.
Y es que esta sección de la web, se había configurado al mismo tiempo como un subdominio y un subdirectorio:
- https://nombrededominio.com/blog/
- https://blog.nombrededominio.com/
Por lo que se estaban duplicando todas las entradas del blog aumentando el riesgo de una penalización por contenidos duplicados. Así que, en este caso, recomendamos mantener la versión del blog en el subdirectorio y redireccionar las entradas del subdominio.
Explicación: Esto se hizo así porque la estrategia de subdirectorios permite aprovechar la autoridad del dominio raíz en todas las secciones mientras que la estrategia por subdominios en la práctica es como si estuviéramos trabajando en una nueva web independiente del dominio raíz.
Así eliminamos el riesgo por los contenidos duplicados y aprovechamos el traspaso de autoridad.
Paso 4: Paginaciones estilo iSocialWeb
Por fin, el día 20 de junio se implementó las paginaciones al estilo de iSocialweb.
Hasta esa fecha, el cliente había mantenido todas las paginaciones en noindex excepto para la primera página y con un rel=”canonical” apuntando a la página principal.
De tal manera que las fichas enlazadas desde las páginas de categorías que no estuvieran en la primera página no recibían fuerza alguna.
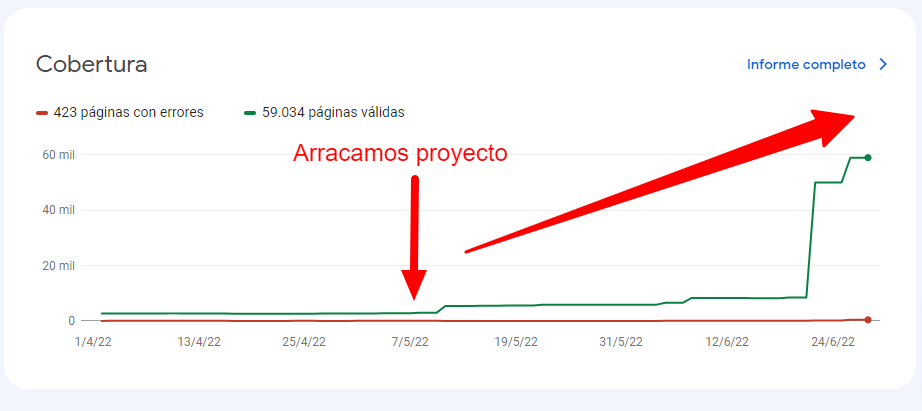
Una vez completada la nueva configuración de las paginaciones, en menos de 48 horas pasamos de 8k URLs indexadas a más de 50k sin necesidad de intervenir.
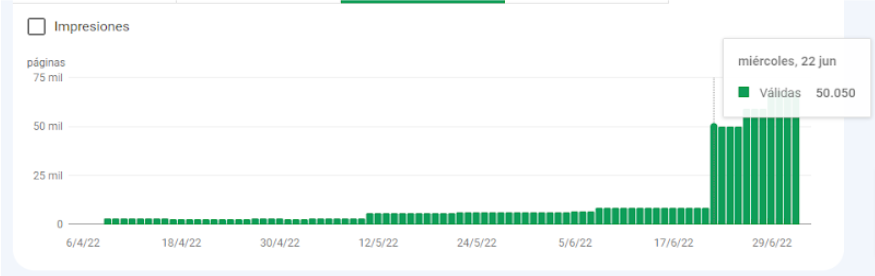
Es decir, al abrir el rastreo a los buscadores, no fue necesario forzar indexación alguna. Una muy buena señal.
Para el día 26 ya contábamos con más de 59k páginas indexadas y para el día 29 de junio 67k. Esto ha supuesto casi duplicar el tráfico orgánico desde que nos pusimos a trabajar en las correcciones el 9 de junio.
Desenlace
Muchas veces en el SEO afirmamos que hay que esperar un tiempo prudente para obtener resultados. Casi siempre hablamos de meses. Sin embargo, a veces es solo cuestión de semanas.
Tal y como puedes comprobar en esta secuencia de gráficos tras los cambios:
Primero, Google empezó a rastrear miles de URLs del dominio que había ignorado hasta ese momento:
Después empezó a indexar el contenido:
Y por último, a posicionar nuestros contenidos y mandar tráfico orgánico:
Unas pocas modificaciones en el robots.txt y en las directivas de indexación han sido suficientes para generar esta subida.
Y es que, cuando tienes:
- Miles de páginas rastreadas sin indexar con valor SEO como ocurría con las fichas de los usuarios.
- URLs excluidas por etiqueta noindex como las paginaciones
- Y versiones en otros idiomas de la web bloqueadas en el robots.txt.
Es relativamente sencillo cambiar la configuración, destapar el rastreo y conseguir que te indexen.
Reflexiones finales Caso de Éxito SEO Indexación
Cuando destapas el rastreo en un proyecto de estas características, hay que ir con mucho cuidado ya que seguro vas a tener miles de problemas con canibalizaciones, contenidos duplicados, URLs vacías o sin interés de posicionamiento indexadas etc…
Afortunadamente, por la tipología del proyecto, la mayoría del contenido sin indexar era original.
Lo cual facilita mucho las cosas.
De forma adicional, se realizaron pequeños cambios de diseño que han ayudado a mejorar las CWV y optimizar los tiempos de carga.
Minimizando de forma notable el riesgo de sufrir problemas con el presupuesto de rastreo asignado por Google al proyecto.
De hecho, es por este motivo por los que muchos proyectos de este tamaño se la pegan o tienen miedo a abrir el rastreo.
Primero porque temen agotar su presupuesto de rastreo y segundo porque una vez abierto no son capaces de gestionar todo lo que viene después: contenidos duplicados, thin content, errores 5XX, etc….
Sin embargo, gracias a la experiencia de iSocialweb esto nunca es un problema.
En realidad:
- Disfrutamos mucho gestionando este tipo de proyectos y todo lo que viene después.
- El auténtico reto llega ahora: controlar bien la indexación.
Así que ya sabes, si necesitas ayuda para optimizar el rendimiento, rastreo e indexación de tu web, ponte en contacto con nosotros y te ayudaremos a que sea todo un éxito.





